
Numpy는 같은 데이터 타입의 배열만 처리 할 수 있다.
pandas는 데이터 타입이 다양하게 섞여있을때도 처리할 수 있다.
#Series
s = pd.Series([1,2,3,4,5])
print(s)
"""
인덱스/데이터(values)
0 1
1 2
2 3
3 4
4 5
dtype: int64
""
print(s.values)
#[1 2 3 4 5]
s=pd.Series(["홍길동", "나길동", "선우길동"])
print(s)
"""
0 홍길동
1 나길동
2 선우길동
dtype: object
"""
subjects=["국어", "영어", "수학"]
s=pd.Series([90,85,80], index=subjects)
print(s)
"""
국어 90
영어 85
수학 80
dtype: int64
"""
import numpy as np
s1 = pd.Series([np.nan,10,30])
s2 = pd.Series([None,10,30]) #둘다 데이터값 없다.
s3 = pd.Series([0,10,30])
s4 = pd.Series([-1,10,30])
print(s1)
print(s2)
print(s3)
print(s4)
"""
0 NaN
1 10.0
2 30.0
dtype: float64
0 NaN
1 10.0
2 30.0
dtype: float64
0 0
1 10
2 30
dtype: int64
0 -1
1 10
2 30
dtype: int64
"""
#값 비교
print(np.nan==np.nan) #값이 다르다.
print(None == None)
print(np.nan is np.nan) #참조는 같다
print(None is None)
"""
False
True
True
True
"""
#날짜 시퀀스
pd.data_range(start= ,end= ,periods= , freq='D) -- 시작, 끝, 날짜 데이터 생성기간, 생성 주기(D=하루씩 증가)
s= pd.date_range(start='2019-01-01',end='2022-02-28')
print(s)
"""
DatetimeIndex(['2019-01-01', '2019-01-02', '2019-01-03', '2019-01-04',
'2019-01-05', '2019-01-06', '2019-01-07', '2019-01-08',
'2019-01-09', '2019-01-10',
...
'2022-02-19', '2022-02-20', '2022-02-21', '2022-02-22',
'2022-02-23', '2022-02-24', '2022-02-25', '2022-02-26',
'2022-02-27', '2022-02-28'],
dtype='datetime64[ns]', length=1155, freq='D')
"""
#DataFrame
data를 담는 틀 -> 라벨이 있는 2차원 데이터를 생성하고 처리할 수 있다.
<형식>
df = pd.DataFrame(data [ , index =index_data , columns = columns_Data])
data에는 리스트와 형태가 유사한 데이터 타입은 모두 사용할 수 있다. matrix형태이다.
->리스트,딕셔너리 타입의 데이터, numpy의 배열 데이터 ,Series,DataFrame
세로축 : index
가로축 : colums
제외한 부분 : values
| index1 / colums1 | coulms2 | coulms3 |
| index2 | values1 | values2 |
df = pd.DataFrame([["길동이",90,80,70],["부길동",80,70,60]])
print(df)
"""
0 1 2 3
0 길동이 90 80 70
1 부길동 80 70 60
"""
print(df.index) #RangeIndex(start=0, stop=2, step=1)
print(df.columns) #RangeIndex(start=0, stop=4, step=1)
print(df.values)
"""
[['길동이' 90 80 70]
['부길동' 80 70 60]]
"""
index와 columns 지정 가능
nums=[1,2]
cnames=["이름","국어","수학","영어"]
df = pd.DataFrame([["길동이",90,80,70],["부길동",80,70,60]] , index =nums ,columns=cnames)
print(df)
"""
이름 국어 수학 영어
1 길동이 90 80 70
2 부길동 80 70 60
"""
딕셔너리 타입의 데이터
table_data ={"연도" : [2020,2021,2022]
,"매출": [200,100,120]}
df = pd.DataFrame(table_data)
print(df)
"""
연도 매출
0 2020 200
1 2021 100
2 2022 120
"""
데이터에 대한 전반적인 정보
df를 구성하는 행,열의 크기, 컬럼명, 컬럼값 자료형
print(df.info())
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 연도 3 non-null int64
1 매출 3 non-null int64
dtypes: int64(2)
memory usage: 176.0 bytes
None
"""
통계량 요약
print(df.describe())
"""
연도 매출
count 3.0 3.000000 총데이터수
mean 2021.0 140.000000 평균
std 1.0 52.915026 표준편차
min 2020.0 100.000000 최소값
25% 2020.5 110.000000 백분위
50% 2021.0 120.000000
75% 2021.5 160.000000
max 2022.0 200.000000 최대값
"""
#dataframe 데이터 연산
Series()와 DataFrame()으로 생성한 데이터는 사칙연산을 할 수 있다.
s1 = pd.Series([1,2,3,4,5])
s2 = pd.Series([6,7,8,9,10])
s3 = s1+s2
print(s1)
print(s2)
print(s3)
"""
0 1
1 2
2 3
3 4
4 5
dtype: int64
0 6
1 7
2 8
3 9
4 10
dtype: int64
0 7
1 9
2 11
3 13
4 15
dtype: int64
"""
#연산 More
s1 =pd.Series([1,2,3,4], index=['a','b','c','d'])
s2 =pd.Series([5,8,7,5], index=['a','b','c','d'])
s3 =s1+s2
print(s3)
"""
a 6
b 10
c 10
d 9
dtype: int64
"""
data1 = {"홍길동":[80,70,78],
"야길동":[78,41,52],
"김길동":[66,22,55]
}
df1 =pd.DataFrame(data1)
data2 = {"홍길동":[77,88,99],
"야길동":[11,22,33],
"김길동":[44,55,66]
}
df2 =pd.DataFrame(data2)
print(df1)
print(df2)
"""
홍길동 야길동 김길동
0 80 78 66
1 70 41 22
2 78 52 55
홍길동 야길동 김길동
0 77 11 44
1 88 22 55
2 99 33 66
"""
df3=df1+df2
print(df3)
"""
홍길동 야길동 김길동
0 157 89 110
1 158 63 77
2 177 85 121
"""
df3.describe()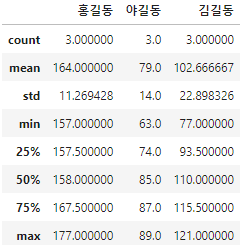
<함수가 DataFrame에 적용되는 방향 지정>
axis = 1 : DataFrame에서 행 단위로 적용됨
axis = 0 : 열 단위
print(df3.mean())
print(df3.mean(axis=1))
"""
print(df3.mean())
print(df3.mean(axis=1))
홍길동 164.000000
야길동 79.000000
김길동 102.666667
dtype: float64
0 118.666667
1 99.333333
2 127.666667
dtype: float64
"""df3
head() , tail() : 처음 / 마지막 행 반환

#CSV파일 읽어오기
df=pd.read_csv('/content/drive/MyDrive/파이썬/iris.csv')
print(df)
"""
sepal.length sepal.width petal.length petal.width variety
0 5.1 3.5 1.4 0.2 Setosa
1 4.9 3.0 1.4 0.2 Setosa
2 4.7 3.2 1.3 0.2 Setosa
3 4.6 3.1 1.5 0.2 Setosa
4 5.0 3.6 1.4 0.2 Setosa
.. ... ... ... ... ...
145 6.7 3.0 5.2 2.3 Virginica
146 6.3 2.5 5.0 1.9 Virginica
147 6.5 3.0 5.2 2.0 Virginica
148 6.2 3.4 5.4 2.3 Virginica
149 5.9 3.0 5.1 1.8 Virginica
[150 rows x 5 columns]
"""df.loc[50] #조건 필터
"""
sepal.length 7.0
sepal.width 3.2
petal.length 4.7
petal.width 1.4
variety Versicolor
Name: 50, dtype: object
"""
#데이터 통합하기
이렇게하면 변화가 없다.
data = {"국어" : [100, 38, 45, 89],
"영어" : [90, 80, 75, 70]}
df1 = pd.DataFrame(data)
print(df1)
"""
국어 영어
0 100 90
1 38 80
2 45 75
3 89 70
"""
data2 = {"국어" : [70, 80],
"영어" : [75, 100]}
df2 = pd.DataFrame(data2)
print(df2)
"""
국어 영어
0 70 75
1 80 100
"""
df1.append(df2)
print(df1)
"""
국어 영어
0 100 90
1 38 80
2 45 75
3 89 70
"""
변수에 넣어서 변화된 객체를 반환할 것.
rdf = df1.append(df2)
print(rdf) #변수에 넣으면 변화ㅇ
print()
print(df1) #df1 변화x
"""
국어 영어
0 100 90
1 38 80
2 45 75
3 89 70
0 70 75
1 80 100
국어 영어
0 100 90
1 38 80
2 45 75
3 89 70
"""
rdf=df.append(df2, ignore_index=True) #default는 false
print(rdf)
"""
국어 영어
0 100 90
1 38 80
2 45 75
3 89 70
4 70 75
5 80 100
"""df3 + df
data3 = {"국어" : [75, 80]}
df3 = pd.DataFrame(data3)
print(df3)
"""
국어
0 75
1 80
"""
print(df)
"""
국어 영어
0 100 90
1 38 80
2 45 75
3 89 70
"""
rdf
rdf = df.append(df3)
print(rdf)
"""
국어 영어
0 100 90.0
1 38 80.0
2 45 75.0
3 89 70.0
0 75 NaN
1 80 NaN
"""
df4+df
data4 = {"수학" : [90,85,88]}
df4 = pd.DataFrame(data4)
print(df4)
"""
수학
0 90
1 85
2 88
"""rdf = df.join(df4)
print(rdf)
"""
국어 영어 수학
0 100 90 90.0
1 38 80 85.0
2 45 75 88.0
3 89 70 NaN
"""
#결측치표현
Missing feature, NA(Not Available) : 표기되지 않은 값 - >머신러닝중 누락된 값
value = np.nan
print(value)
#nan
value2 = None
print(value2)
#None
se1 = pd.Series([남궁길', '선우길', np.nan, '독고길'])
se1.isnull() #결측치 여부 확인
"""
0 False
1 False
2 True
3 False
dtype: bool
"""#se1.info()
se1[0] = np.nan
print(se1)
"""
0 NaN
1 선우길
2 NaN
3 독고길
dtype: object
"""se1[1] = None
print(se1)
"""
0 NaN
1 None
2 NaN
3 독고길
dtype: object
"""non ,none는 빈값
se1.isnull()
"""
0 True
1 True
2 True
3 False
dtype: bool
"""se1.notnull()
"""
0 False
1 False
2 False
3 True
dtype: bool
"""
dropna( ) : NaN 값이 있는 데이터 제거
#전처리 과정에서 결측 데이터 제외하기
se2=se1.dropna()
print(se2)
"""
3 독고길
dtype: object
"""
df1 = pd.DataFrame([[1, np.nan, 3,4], [np.nan,np.nan,np.nan,np.nan], [3,4,1,1]])
print(df1)
"""
0 1 2 3
0 1.0 NaN 3.0 4.0
1 NaN NaN NaN NaN
2 3.0 4.0 1.0 1.0
"""#하나라도 결측치일 때 해당 Row(index)를 삭제
df2=df1.dropna()
print(df2)
"""
0 1 2 3
2 3.0 4.0 1.0 1.0
"""모든 컬럼이 결측치일 때 해당 Row(index)를 삭제
df3 = df1.dropna(how='all')
print(df3)
"""
0 1 2 3
0 1.0 NaN 3.0 4.0
2 3.0 4.0 1.0 1.0
"""'PYTHON > 데이터분석' 카테고리의 다른 글
| 통계분석시각화 - 타이타닉2 (0) | 2023.09.15 |
|---|---|
| 통계분석시각화 - 타이타닉1 (0) | 2023.09.15 |
| 통계분석시각화 : matplotlib (1) | 2023.09.15 |
| 통계분석시각화 : Numpy -연산 (0) | 2023.09.15 |
| 통계분석시각화 : Numpy -소개 (0) | 2023.09.15 |

