통계분석시각화 - 타이타닉1PYTHON/데이터분석2023. 9. 15. 17:14
Table of Contents
Pandas : 데이터분석 라이브러리, 관계형 데이터를 행과 열로 구성된 객체로 만들어준다.
Matplotlib : 시각화 라이브러리, 그래프를 그릴 수 있게 해주는 도구
Numpy : 선형대수 라이브러리 , 벡터, 행렬 등 수치 연산
df : 데이터 프레임
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#csv 파일 읽기
path = '/content/sample_data/train_titanic.csv'
df = pd.read_csv(path)
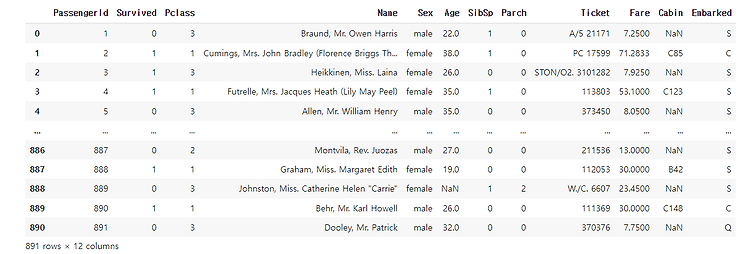
df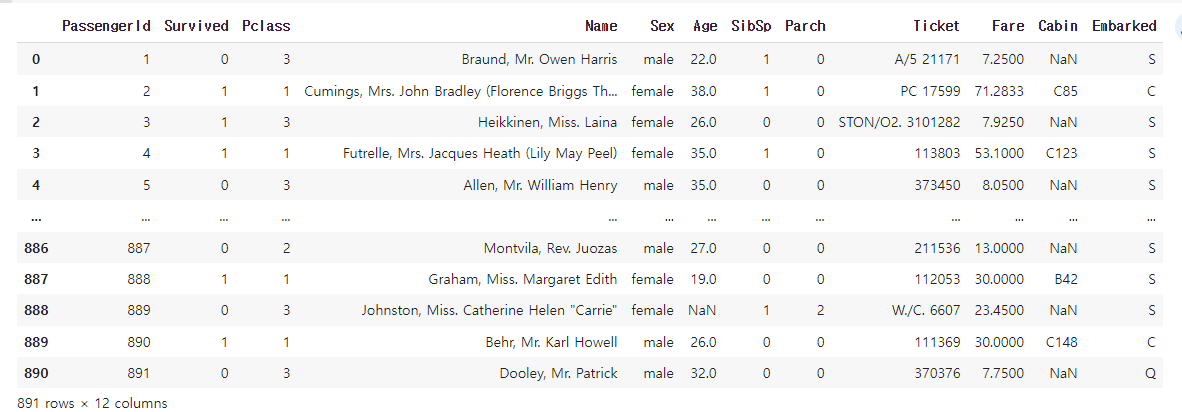
1. 주어진 자료의 인원, 생존자, 사망자는 몇 명인가?
데이터 값 세기 : count( )
카테고리별 값 세기 : df[ ].value_counts( ) - 둘다 특정 column에 적용가능
df['Survived'].value_counts() #1생존자 , 0 사망자
"""
0 549
1 342
Name: Survived, dtype: int64
"""count = df['PassengerId'].count() #인원세기
sur_data = df['Survived'] #생존자, 사망자
print(type(sur_data)) #Series타입출력
svc = sur_data.value_counts() #sur_data 카테고리값을 세겠다
print(type(svc)) #series는 인덱스와 value가 있는 1차원 시퀸스 데이터.
sur_data.count()
#0 사망자,1 생존자 , 인덱스를 통해 값세기
print(f"인원 : {sur_data.count()}, 사망자수 : {svc.values[0]}, 생존자 수 : {svc.values[1]}")
"""
<class 'pandas.core.series.Series'>
<class 'pandas.core.series.Series'>
인원 : 891, 사망자수 : 549, 생존자 수 : 342
"""
2. 생존자와 사망자를 Pie 그래프로 나타내고 생존자와 사망자의 퍼센트를 소수점 2자리까지 나타내시오.
labels=["dead" , "alive"] #라벨
plt.pie(svc, labels=labels, autopct="%.2f" )
plt.show()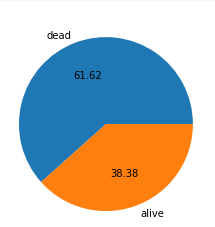
3. 결측데이터가 있는 컬럼들을 조사하시오.
결측치 : 대부분의 머신러닝 알고리즘은 누락된 데이터가 존재한다. -> 처리해야 함
isnull() : 결측치 여부 확인, 결측치에 대해 True값 반환
isnull().value_counts() : 결측치 개수 확인
df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
"""
이처럼 대부분의 데이터에 결측치가 존재한다.
df['Age'].isnull().value_counts()
"""
False 714
True 177
Name: Age, dtype: int64
"""
df['Cabin'].isnull().value_counts()
"""
True 687
False 204
Name: Cabin, dtype: int64
"""
df['Embarked'].isnull().value_counts()
"""
False 889
True 2
Name: Embarked, dtype: int64
"""
4. Pclass의 종류별로 분포를 Pie 그래프로 나타내시오.
sort_index() : index를 기준
sort_values() : 컬럼 값 기준으로 데이터를 정렬
dvc = df.Pclass.value_counts().sort_index() #Pclass의 값을 인덱스 기준으로 정렬
plt.pie(dvc.values , labels=['1','2','3'] ,autopct="%.2f")
plt.title("Pclass")
plt.show()
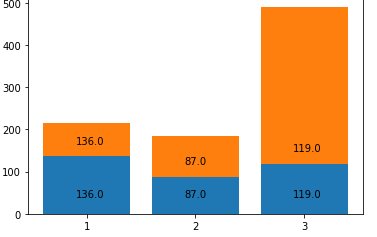
5. Pclass의 종류별로 생존자와 사망자를 하나의 막대그래프로 나타내시오. (아래:생존자, 위:사망자)
pdata = df.Pclass #pdata : Pclass에 관한 데이터 프레임
cn = len(pdata.unique()) #pdata의 고유값 길이 수 = 값의 종류 확인
pc_alive_arr = np.zeros(cn) #numpy
pc_dead_arr = np.zeros(cn)
for index in range(len(pdata)):
pi = pdata[index]-1 # Pclass는 1,2,3인데 이를 0,1,2로 변환
if sur_data[index]==0: #죽은 승객일 때
pc_dead_arr[pi] +=1
else: #생존
pc_alive_arr[pi] +=1
pc_alive_arr, pc_dead_arr #클래스1,2,3 별로 살아있는 ... (array([136., 87., 119.]), array([ 80., 97., 372.]))
labels=['1','2','3']
plt.bar(labels,pc_alive_arr) #막대그래프 그리기
plt.bar(labels,pc_dead_arr , bottom=pc_alive_arr)
for i in range(cn):
plt.annotate(str(pc_alive_arr[i]) ,(-0.1+i,40)) #annotate:주석 ->파란색 부분
plt.annotate(str(pc_alive_arr[i]) ,(-0.1+i,pc_alive_arr[i]+30))
plt.show()
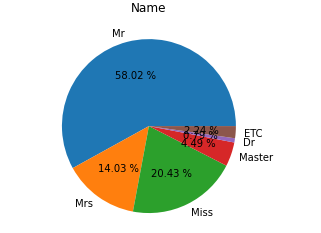
6. Name 컬럼에 탑승자를 부르는 호칭을 Mr, Mrs, Miss, Master, Dr, ETC로 나누어 분포를 파이 그래프로 나타내시오.
df.Name
names_values=['Mr', 'Mrs', 'Miss', 'Master', 'Dr', 'ETC']
#names_values 중에 몇 번째 것인지 판별하는 함수
def get_name_index(name):
first, second= name.split(',')#split: ,를 기준으로 앞뒤로 분리시켜서 뒤쪽 데이터만 사용
foos = second.split('.' )#뒤의 데이터 중에서도 .을 기준으로 분리, 그런데 .이 있지 않은 것도 있어서 컬렉션을 받고
tn = foos[0].replace(' ','') #공백 없애기.
for index, nv in enumerate(names_values): #names_values
if nv == tn: #tn : name에서 가져옴
return index
return 5
n_cnts = np.zeros(6) #names_values 길이만큼을 원소값0 array로 만들기
for i, name in enumerate(df.Name):
ni = get_name_index(name)
n_cnts[ni] +=1
#print(n_cnts)
plt.pie(n_cnts, labels=names_values, autopct="%.2f %%")
plt.title("Name")
plt.show()
7. 앞에서 구분한 호칭에 따른 생존자와 사망자를 하나의 막대그래프로 나타내시오.(아래:생존자, 위:사망자)
pn_alive_arr = np.zeros(6) #생존
pn_dead_arr = np.zeros(6) #사망
for i,name in enumerate(df.Name):
ni = get_name_index(name) #nu : name의 인덱스 뽑기
if sur_data[i]==0:
pn_dead_arr[ni]+=1
else:
pn_alive_arr[ni]+=1
#표그리기
plt.bar(names_values, pn_alive_arr) #6번에 name_values정의
plt.bar(names_values, pn_dead_arr, bottom = pn_alive_arr)
for i in range(6):
plt.annotate(str(pn_alive_arr[i]),(-0.1+i,40))
if pn_alive_arr[i]<40:
plt.annotate(str(pn_dead_arr[i]),(-0.1+i, pn_alive_arr[i]+80))
else:
plt.annotate(str(pn_dead_arr[i]),(-0.1+i, pn_alive_arr[i]+80))
plt.show()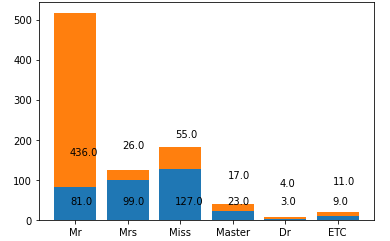
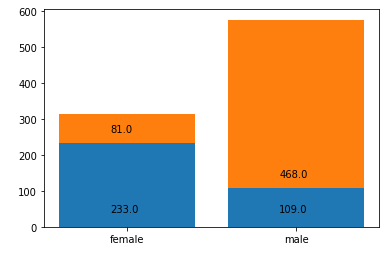
8. 성별로 분포를 파이 그래프로 나타내시오.
dvc = df.Sex.value_counts().sort_index()
plt.pie(dvc.values , labels=['female','man'] ,autopct="%.2f") #dvc 값을 그래프 안에 적기
plt.title("sex")
plt.show() #0남자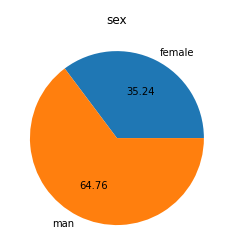
'PYTHON > 데이터분석' 카테고리의 다른 글
| 통계분석시각화 - 통합 (1) | 2023.09.15 |
|---|---|
| 통계분석시각화 - 타이타닉2 (0) | 2023.09.15 |
| 통계분석시각화 : matplotlib (1) | 2023.09.15 |
| 통계분석시각화-pandas (0) | 2023.09.15 |
| 통계분석시각화 : Numpy -연산 (0) | 2023.09.15 |