통계분석시각화 - 타이타닉2PYTHON/데이터분석2023. 9. 15. 17:14
Table of Contents
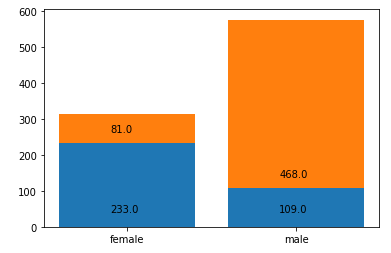
9. 성별에 따른 생존자와 사망자를 하나의 막대그래프로 나타내시오.(아래:생존자, 위:사망자)
sdata = df.Sex #성별 데이터 프레임
sn = len(sdata.unique()) #sn : sdata의 값개수
ps_alive_arr = np.zeros(sn) #0으로 초기화
ps_dead_arr = np.zeros(sn)
for index in range(len(sdata)):#sdata개수만큼
if sdata[index] =='female': #인덱스가 female이면
si =0 #si에 0넣고
else:
si =1
if sur_data[index] ==0: #죽은 승객일때
ps_dead_arr[si]+=1
else:
ps_alive_arr[si]+=1
labels=['female','male'] #x축라벨
plt.bar(labels,ps_alive_arr)
plt.bar(labels,ps_dead_arr , bottom=ps_alive_arr)
for i in range(sn):
plt.annotate(str(ps_alive_arr[i]) ,(-0.1+i,40))
plt.annotate(str(ps_dead_arr[i]) ,(-0.1+i,ps_alive_arr[i]+30))
plt.show()
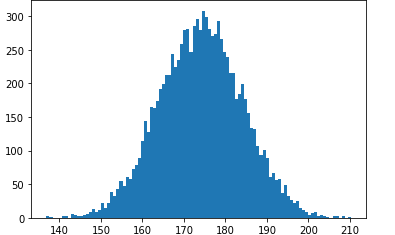
10. 나이를 5살 범위로 17단계로(0~5, 5~10,...,80~85)로 나누어 분포를 조사하여 파이 그래프로 나타내시오.(결측값은 평균나이로 처리하시오.)
mv = df.Age.mean() #평균
ad = df.Age.fillna(mv) #결측치 수정
ad.isnull().value_counts() #확인
"""
False 891
Name: Age, dtype: int64
"""
#히스토그램 도수분포표 막대그래프로 시각화
n, bins, patches = plt.hist(ad,bins =[0,5,10,15,20,25,30,35,40,45,50,55,60,65,70,75,80,85])
plt.show()
n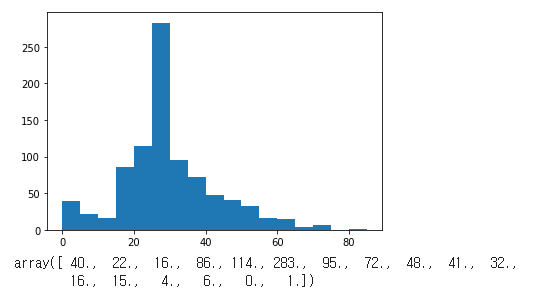
age_values = np.zeros(17)
for i, age in enumerate(ad): #ad : 결측치 수정한 값만큼 반복
ai = age//5
ai = int(ai)
age_values[ai] +=1
age_values
"""
array([ 40., 22., 16., 86., 114., 283., 95., 72., 48., 41., 32.,
16., 15., 4., 6., 0., 1.])
"""
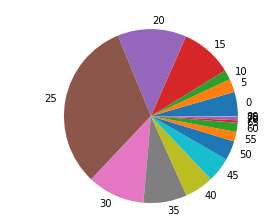
plt.pie(age_values ,labels=['0','5','10','15','20','25','30','35','40','45','50','55','60','65','70','75','80'])
plt.show()
11. 나이를 구분한 단계에 따른 생존자와 사망자를 하나의 막대그래프로 나타내시오.(아래:생존자, 위:사망자)
ps_alive_arr = np.zeros(17)
ps_dead_arr = np.zeros(17)
for index in range(len(ad)): #ad 위쪽에 결측치 수정한 값
ai = ad[index]//5
ai = int(ai)
if sur_data[index]==0: #죽은 승객일 때
ps_dead_arr[ai]+=1
else: #생존 승객일 때
ps_alive_arr[ai]+=1
labels=['0','5','10','15','20','25','30','35','40','45','50','55','60','65','70','75','80']
plt.bar(labels,ps_alive_arr)
plt.bar(labels,ps_dead_arr,bottom=ps_alive_arr)
plt.show()
for i in range(17):
print(f"{i*5:02d} ~ {(i+1)*5:-02d}: {age_values[i]:03.0f}")
plt.show()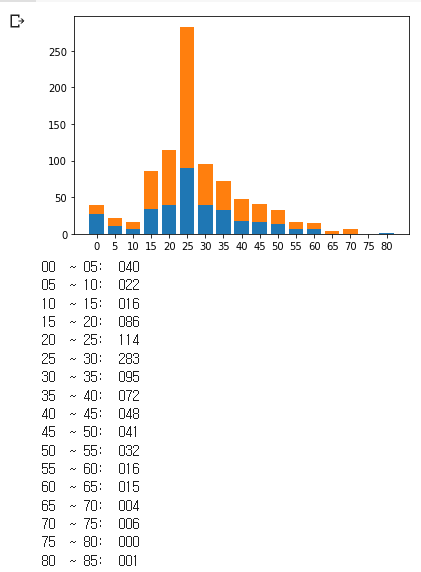
12. SibSp 컬럼의 값의 종류에 따른 분포를 조사하여 파이 그래프로 나타내시오.
svc = df.SibSp.value_counts().sort_index()
plt.pie(svc.values , labels=svc, autopct="%.2f")
plt.title("SibSp")
plt.show()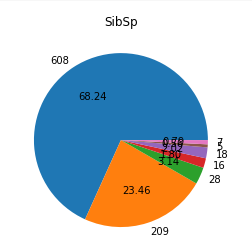
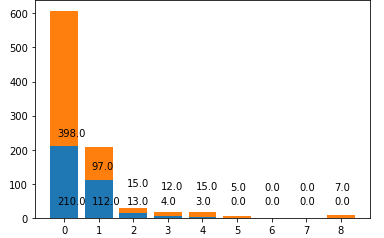
13. 값에 따른 생존자와 사망자를 하나의 막대그래프로 나타내시오.(아래:생존자, 위:사망자)
sdata = df.SibSp
sn = 9 #형제 자매 수를 인덱스로 사용하기 위해서 0~8개까지 9개를 사용
sc_alive_arr = np.zeros(sn)
sc_dead_arr = np.zeros(sn)
for index in range(len(sdata)):
si = sdata[index] #형제 자매수를 얻어온다.
if sur_data[index] ==0: #죽은 승객일때
sc_dead_arr[si]+=1
else:
sc_alive_arr[si]+=1
labels=[str(i) for i in range(9)]
plt.bar(labels,sc_alive_arr)
plt.bar(labels,sc_dead_arr , bottom=sc_alive_arr)
for i in range(sn):
plt.annotate(str(sc_alive_arr[i]) ,(-0.2+i,40))
if sc_alive_arr[i] <40:
plt.annotate(str(sc_dead_arr[i]) ,(-0.2+i,sc_alive_arr[i]+80))
else:
plt.annotate(str(sc_dead_arr[i]) ,(-0.2+i,sc_alive_arr[i]+30))
plt.show()
14. Parch 컬럼의 값의 종류에 따른 분포를 조사하여 파이 그래프로 나타내시오.
pvc = df.Parch.value_counts().sort_index()
plt.pie(pvc.values, labels=pvc.index,autopct="%.2f")
plt.title("Parch")
plt.show()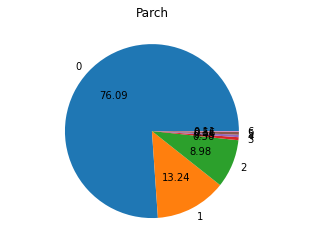
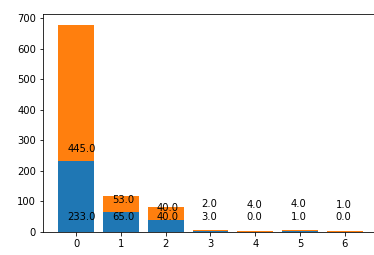
15. 값에 따른 생존자와 사망자를 하나의 막대그래프로 나타내시오.(아래:생존자, 위:사망자)
pdata = df.Parch
pn = 7 #직계 자손, 조상수를 인덱스로 사용하기 위해 0~6까지 7개 새용
pc_alive_arr = np.zeros(pn)
pc_dead_arr = np.zeros(pn)
for index in range(len(pdata)):
pi = pdata[index] #직계 자손, 조상 수
if sur_data[index] ==0: #죽은 승객일때
pc_dead_arr[pi]+=1
else:
pc_alive_arr[pi]+=1
labels=[str(i) for i in range(pn)]
plt.bar(labels,pc_alive_arr)
plt.bar(labels,pc_dead_arr , bottom=pc_alive_arr)
for i in range(pn):
plt.annotate(str(pc_alive_arr[i]) ,(-0.2+i,40))
if pc_alive_arr[i] <40:
plt.annotate(str(pc_dead_arr[i]) ,(-0.2+i,pc_alive_arr[i]+80))
else:
plt.annotate(str(pc_dead_arr[i]) ,(-0.2+i,pc_alive_arr[i]+30))
plt.show()
16. 승선한 항구(Embarked 컬럼)에 따른 분포를 조사하여 파이 그래프로 나타내시오.(결측값은 'N'으로 마킹하시오.)
df.Embarked.isnull().value_counts()
"""
False 889
True 2
Name: Embarked, dtype: int64
"""
edata = df.Embarked.fillna('N')
edata.isnull().value_counts()
"""
False 891
Name: Embarked, dtype: int64
"""
evc = edata.value_counts().sort_index()
plt.pie(evc.values, labels=evc.index,autopct="%.2f")
plt.title("Embarked")
plt.show()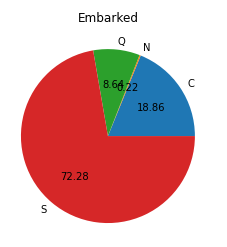
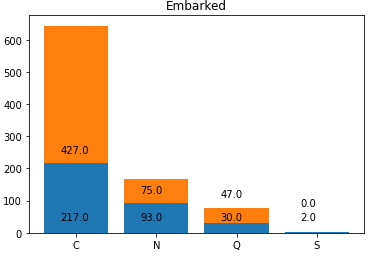
17. 값에 따른 생존자와 사망자를 하나의 막대그래프로 나타내시오.(아래:생존자, 위:사망자)
#edata.unique() #array(['S', 'C', 'Q', 'N'], dtype=object)
len(edata.unique())
def get_embarked_index(embarked):
if embarked =='S':
return 0
if embarked =='C':
return 1
if embarked =='Q':
return 2
if embarked =='N':
return 3
edata.unique() #값의 종류 확인
en = len(edata.unique()) #승선한 항구 수
ec_alive_arr = np.zeros(en)
ec_dead_arr = np.zeros(en)
for index in range(len(edata)):
ei = get_embarked_index(edata[index]) #embarked의 인덱스 얻어온다
if sur_data[index]==0: #사망 승객
ec_dead_arr[ei]+=1
else: #생존 승객
ec_alive_arr[ei]+=1
labels=evc.index
plt.bar(labels,ec_alive_arr)
plt.bar(labels,ec_dead_arr,bottom=ec_alive_arr)
for i in range(en):
plt.annotate(str(ec_alive_arr[i]),(-0.2+i, 40))
if ec_alive_arr[i]<40:
plt.annotate(str(ec_dead_arr[i]),(-0.2+i, ec_alive_arr[i]+80))
else:
plt.annotate(str(ec_dead_arr[i]),(-0.2+i, ec_alive_arr[i]+30))
plt.title('Embarked')
plt.show()
'PYTHON > 데이터분석' 카테고리의 다른 글
| 데이터 분석에 자주 사용하는 문법 (0) | 2023.09.15 |
|---|---|
| 통계분석시각화 - 통합 (1) | 2023.09.15 |
| 통계분석시각화 - 타이타닉1 (0) | 2023.09.15 |
| 통계분석시각화 : matplotlib (1) | 2023.09.15 |
| 통계분석시각화-pandas (0) | 2023.09.15 |