
1-3 처럼...
도미 35마리와 빙어 14마리를 모두 저장하고 맞추는 거라면 100%달성하는게 당연하지 않나요?
어떤것이 도미이고 빙어인지 알고 있는데 맞추지 못하는것이 이상하잖아..
다시..생각해보자~!~!~!^^
#지도학습, 비지도학습
머신러닝 알고리즘은 지도학습과 비지도 학습으로 나뉜다.
지도 학습 알고리즘
훈련하기 위한 데이터와 정답이 필요,
타깃(정답)이 있으니 알고리즘이 정답 맞히는 것을 학습한다. -> 도미인지..빙어인지... KNN알고리즘도 여기에 해당
[훈련데이터] =입력+타깃
[입력(데이터)] [타깃(정답)]
[[25.4 ,242.0]] [1]
(길이,무게->특성)
비지도 학습 알고리즘
타깃없이 입력데이터만 사용
#훈련 세트와 테스트 세트
도미와 빙어의 데이터와 타겟을 주고 훈련한 다음 같은 데이터로 테스트를 한다면 모두 맞히는 것이 당연하다.
머신러닝의 알고리즘 성능을 제대로 평가하려면 훈련데이터와 평가에 사용할 데이터가 각각 달라야한다.
-> 평가를 위해 또 다른 데이터를 준비 or 이미 준비한 데이터 중 일부를 떼어내어 활용한다.
후자를 사용
평가에 사용하는 데이터를 테스트 세트, 훈련에 사용되는 데이터를 훈련세트 라고 부른다.

도미와 빙어의 데이터를 합쳐 하나의 파이썬 리스트로 준비한다.
fish_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0, 9.8,
10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
fish_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0, 6.7,
7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
두 파이썬 리스트를 순회하면서 각 생선의 길이와 무게를 하나의 리스트로 담은 2차원 리스트 만든다.
fish_data = [[l, w] for l, w in zip(fish_length, fish_weight)]
fish_target = [1]*35 + [0]*14
이때 하나의 생선 데이터를 샘플이라고 부른다.
도미 35마리 빙어 14마리 총 49개의 샘플이 있다.
사용하는 특성 : 길이, 무게
이 데이터의 처음 35개를 훈련세트 , 14개를 테스트 세트로 사용한다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
이제 전체 데이터에서 처음 35개를 선택해야 한다.
fish_data의 다섯번째 샘플을 출력한다면 다음과 같이 쓴다.
print(fish_data[4])
#[29.0, 430.0]
파이썬의 슬라이싱을 써서 5개 샘플 선택한다.
#훈련세트로 입력값 중 0~34번째 인덱스 사용 : 도미
train_input = fish_data[:35]
#훈련세트로 타깃값 중 ~
train_target = fish_target[:35]
#테스트 세트 35~마지막 : 빙어
test_input = fish_data[35:]
test_target = fish_target[35:]인덱스 0~34 : 훈련 세트
35~마지막 : 테스트 세트
훈련세트로 fit() 메서드를 호출해 모델을 훈련하고
테스트 세트로 score() 메서드를 호출해 평가하자
kn = kn.fit(train_input, train_target)
kn.score(test_input, test_target)
#0.0엥 뭐죠 정확도가 0이 되어버렸다.. 최악의 성능이 되어버렸다.. 뭘 잘못한걸까 ???
#샘플링 편향
위처럼 마지막 14개를 테스트 세트로 떼어 놓으면 훈련세트에는 빙어가 하나도 없어...
빙어 없이 모델을 훈련하면 빙어를 올바르게 분류할 수 없다
훈련세트와 테스트 세트에 샘플이 골고루 섞여있지 않으면 샘플링이 한쪽으로 치우쳤다는 의미로
샘플링 편향이라고 부른다.
훈련테스트와 테스트 세트를 나누려면 도미와 빙어를 골고루 섞이게 만들어야 한다.
->넘파이로 해결
#넘파이
고차원 배열을 손쉽게 조작할 수 있는 배열 라이브러러리이다.
리스트로 2차원리스트로 표현할 수 있지만 고차원 리스트를 표현하려면 ...매우 번거롭다.
import numpy as np리스트 -> 넘파이배열로 바꾸기
input_arr = np.array(fish_data)
target_arr = np.array(fish_target)출력
print(input_arr)
[[ 25.4 242. ]
[ 26.3 290. ]
[ 26.5 340. ]
[ 29. 363. ]
[ 29. 430. ]
[ 29.7 450. ]
[ 29.7 500. ]
[ 30. 390. ]
[ 30. 450. ]
[ 30.7 500. ]
[ 31. 475. ]
[ 31. 500. ]
[ 31.5 500. ]
[ 32. 340. ]
[ 32. 600. ]
[ 32. 600. ]
[ 33. 700. ]
[ 33. 700. ]
[ 33.5 610. ]
[ 33.5 650. ]
[ 34. 575. ]
[ 34. 685. ]
[ 34.5 620. ]
[ 35. 680. ]
[ 35. 700. ]
[ 35. 725. ]
[ 35. 720. ]
[ 36. 714. ]
[ 36. 850. ]
[ 37. 1000. ]
[ 38.5 920. ]
[ 38.5 955. ]
[ 39.5 925. ]
[ 41. 975. ]
[ 41. 950. ]
[ 9.8 6.7]
[ 10.5 7.5]
[ 10.6 7. ]
[ 11. 9.7]
[ 11.2 9.8]
[ 11.3 8.7]
[ 11.8 10. ]
[ 11.8 9.9]
[ 12. 9.8]
[ 12.2 12.2]
[ 12.4 13.4]
[ 13. 12.2]
[ 14.3 19.7]
[ 15. 19.9]]배열의 크기를 알려주는 shape 속성
print(input_arr.shape)
#(49, 2)랜덤하게 샘플을 선택해 훈련 세트와 테스트 세트로 만든다.
무작위로 샘플을 고른다
주의할 점 : input_arr , target_arr에서 같은 위치는 함께 선택되어야 한다.
26.3,290 1
| 0 |
| 1 |
| ... |
| 48 |
0~48까지의 인덱스
| 13 |
| 45 |
| 47 |
| 38 |
랜덤하게 섞은 인덱스 ->훈련세트35개 , 테스트세트 14개
넘파이 arrange()함수를 사용해서 0부터 48까지 1씩 증가하는 인덱스를 만들고 랜덤하게 섞는다.
np.random.seed(42) #난수를 생성하기 위한 정수 초깃값 랜덤함수의 결과를 동일하게 재현하고 싶을때 사용
index = np.arange(49)
np.random.shuffle(index)
0부터 48까지 정수가 잘 섞였다.
print(index)
"""
[13 45 47 44 17 27 26 25 31 19 12 4 34 8 3 6 40 41 46 15 9 16 24 33
30 0 43 32 5 29 11 36 1 21 2 37 35 23 39 10 22 18 48 20 7 42 14 28
38]
"""
랜덤하게 섞인 인덱스를 사용해 전체 데이터를 훈련세트와 테스트 세트로 나눈다.
배열인덱싱 사용한다.
1개의 인덱스가 아닌 여러개의 인덱스로 한번에 여러개의 원소를 선택한다.
두번째와 네번째 샘플 선택해 출력
print(input_arr[[1,3]])
"""
[[ 26.3 290. ]
[ 29. 363. ]]
"""
넘파이 배열을 인덱스로 전달 할 수도 있다.
index 배열의 처음 35개를 input_arr와 target_arr에 전달해 랜덤하게 35개 샘플을 훈련세트로 만든다.
train_input = input_arr[index[:35]]
train_target = target_arr[index[:35]]만들어진 index 첫번째 값은 13이다. 따라서 train_input의 첫번째 원소는 input_arr의 열네번째 원소가 들어있을 것이다.
print(input_arr[13], train_input[0])
#[ 32. 340.] [ 32. 340.]나머지 14개도 테스트 세트로 만든다.
test_input = input_arr[index[35:]]
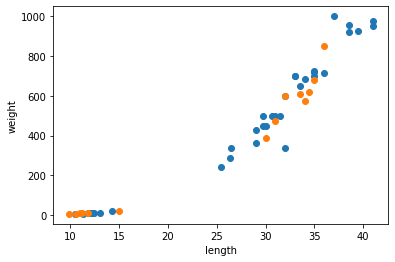
test_target = target_arr[index[35:]]훈련세트, 테스트 세트에 도미와 빙어가 잘 섞였는지 산점도로 그린다.
import matplotlib.pyplot as plt
plt.scatter(train_input[:, 0], train_input[:, 1])
plt.scatter(test_input[:, 0], test_input[:, 1])
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
#두번째 머신러닝 프로그램
훈련세트와 테스트 세트로 KNN 훈련시킨다.
fit( )를 실행할때마다 KNeighborsClassfier 클래스의 객체는 이전에 학습한 모든걸 잃어버린다.
kn = kn.fit(train_input, train_target)인덱스를 섞어 만든 train_input과 train_target으로 모델을 훈련 시킨후 테스트 -> score()
kn.score(test_input, test_target)테스트 세트의 예측결과와 실제 타깃 확인 ->predict()
kn.predict(test_input)
"""
array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])
"""test_target
"""
array([0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 0])
"""array 값으로 감싸져 있다.. 넘파이 배열을 반환하고 있는 것이다.
'PYTHON > 데이터분석' 카테고리의 다른 글
| 3-1 KNN 회귀 (0) | 2023.09.15 |
|---|---|
| 2-2 데이터 전처리 (0) | 2023.09.15 |
| 1-3 마켓과 머신러닝 (0) | 2023.09.15 |
| 통계 데이터 분석 -KNN회귀 (0) | 2023.09.15 |
| 통계 데이터 분석 -확률 (0) | 2023.09.15 |



