
다항 회귀로 농어의 무게를 어느정도 예측할 수 있지만
여전히 훈련세트 점수 < 테스트세트 점수 =과소적합이다.
전에는 길이라는 1개의 특성을 사용해 선형회귀 모델을 훈련시켰다.
여러개의 특성을 사용한 선형회귀를 다중회귀라고 한다.
1개의 특성을 사용했을때 선형회귀 모델이 학습하는 것은 직선이다.
2개의 특성은 평면을 학습한다.
3개의 특성은 각 특성을 서로 곱해서 새로운 특성을 만들어 낸다. (농어 길이 * 농어 높이)
기존의 특성을 사용해 새로운 특성을 뽑아내는 작업을 특성공학이라고 한다.
사이킷런에서는 도구를 제공한다.
#데이터 준비
농어의 특성이 3개로 늘어났기 때문에..복잡하다.
인터넷에서 데이터를 바로 다운로드하여 사용하자. -> 넘파이 불가, 판다스만 가능
판다스
유명한 데이터 분석 라이브러리, 데이터프레임은 판다스의 핵심 데이터 구조로 넘파이 배열로 쉽게 바꿀 수 있다.
import pandas as pd농어데이터 -> 길이 높이 두께
df = pd.read_csv('https://bit.ly/perch_csv_data') #read_csv로 파일 읽기
perch_full = df.to_numpy() #넘파이 배열로 바꾼다.
print(perch_full)
"""
[[ 8.4 2.11 1.41]
[13.7 3.53 2. ]
[15. 3.82 2.43]
~~~"""
타깃데이터(무게) -> 무게를 예측해야 하니까
import numpy as np
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)타깃데이터(무게) 준비
import numpy as np
perch_weight = np.array(
[5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0]
)
타깃데이터를 훈련세트, 테스트 세트로 나누기
사이킷런의 train_test_split( ) 함수를 통해 나누었다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target
= train_test_split(perch_full, perch_weight, random_state=42)
<모델클래스 참고>
모델객체를 만들고
훈련세트로 fit() 메서드로 모델을 훈련하고
테스트 세트로 score() 메서드를 호출해 평가
테스트 세트의 예측결과와 실제 타깃 확인 ->predict()
#사이킷런의 변환기
사이킷런은 특성을 만들거나 전처리하기 위한 다양한 클래스를 제공한다
이런 클래스를 변환기라고 부른다.
모델 클래스에 fit,score,predict 메서드가 있는것 처럼
변환기 클래스에는 fit , transform 메서드를 제공한다
<예시>
from sklearn.preprocessing import PolynomialFeatures2개의 특성 2,3으로 이루어진 샘플 적용
클래스 객체를 만든 다음
fit() : 새롭게 만들 특성 조합을 찾는다.
transform() : 실제로 데이터 변환
두개 호출
poly = PolynomialFeatures()
poly.fit([[2, 3]])
print(poly.transform([[2, 3]]))
#[[1. 2. 3. 4. 6. 9.]]fit을 보자
변환기는 입력 데이터를 변환하는데 타깃 데이터가 필요하지 않다.
따라서 모델클래스와는 다르게 fit 메서드에 입력데이터만 전달했다.
즉 여기서 2개의 특성을 가진 샘플[2,3]이
6개의 특성을 가진 #~ 결과창으로 바뀌었다.
2와 3을 제곱한 4,9가 추가 되었다.
2와 3을 곱한 6도 호출되었다.
1은 뭐냐 ? -> 자동으로 절편 추가 ..필요없다 -> include_bias =False로 다시
poly = PolynomialFeatures(include_bias=False)
poly.fit([[2, 3]])
print(poly.transform([[2, 3]]))
#[[2. 3. 4. 6. 9.]]
<다시시작>
train_input을 변환한 데이터를 train_poly에 저장하고
poly = PolynomialFeatures(include_bias=False)
poly.fit(train_input) #새로운 특성 찾기
train_poly = poly.transform(train_input) #데이터변환이 배열의 크기를 확인하자
print(train_poly.shape)
#(42, 9)
PolynomialFeatures 클래스는 9개의 특성이 어떻게 만들어졌는지 확인할 수있다.
poly.get_feature_names_out()
"""
array(['x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2',
'x2^2'], dtype=object)
"""테스트 세트 변환
test_poly = poly.transform(test_input)
이제 변환된 특성을 사용하여 다중 회귀 모델을 훈련하자
#다중 회귀 모델 훈련하기
train_poly를 사용해 모델을 훈련시키자
다항 특성을 추가했더니 높은 점수가 나왔다. 특성이 늘어나면 선형회귀의 능력은 매우 강해진다.
from sklearn.linear_model import LinearRegression #선형회귀
lr = LinearRegression()
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
#0.9903183436982124테스트 세트 점수확인 -> 과소적합 해결완
print(lr.score(test_poly, test_target))
#0.9714559911594134degree로 특성 더 많이 추가
poly = PolynomialFeatures(degree=5, include_bias=False)
poly.fit(train_input)
train_poly = poly.transform(train_input)
test_poly = poly.transform(test_input)만들어진 특성의 개수가 55개나 된다.
print(train_poly.shape)
#(42, 55)이 데이터를 사용해 선형 회귀 모델을 다시 훈련하자
거의 완벽한 점수다
lr.fit(train_poly, train_target)
print(lr.score(train_poly, train_target))
#0.9999999999991097테스트 세트의 점수 확인하자
음수가 나온다.. 이상하다
특성의 개수를 크게 늘리면 선형모델은 아주 강력해진다. 훈련세트에 대해 거의 완벽하게 학습할 수있다.
하지만 훈면 세트에 너무 과대적합되므로 테스트 세트에서는 형편없는 점수가 나온다.
다시 특성을 줄여보자
print(lr.score(test_poly, test_target))
#-144.40579242684848
#규제
머신러닝 모델이 훈련세트를 너무 과도하게 학습하지 못하도록 훼방놓는다.
모델이 훈련세트에 과대적합되지 않도록 만드는 것이다.
선형회귀 모델의 경우 특성에 곱해지는 (계수=기울기)의 크기를 작게 만드는 것이다.
기울기를 줄여 보편적인 학습 패턴을 만든다.
앞서 55개의 특성으로 훈련한 선형회귀모델의 계수를 규제하여
훈련세트의 점수를 낮추고
대신 테스트 세트의 점수를 높이겠다.
일반적으로 선형회귀모델에 규제를 적용할때 기울기의 크기가 서로 많이 다르면 공정하지 않을것이다.
규제를 적용하기 전에 먼저 정규화를 하자
저번엔 표준점수로 바꿨지만 사이킷런의 StandardScaler 클래스를 사용하자 (변환기)
중요
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_poly) #훈련세트로 학습한 변환기를 사용해 테스트세트까지 변환할것
#표준점수로 변환되었다.
train_scaled = ss.transform(train_poly)
test_scaled = ss.transform(test_poly)
이렇게 선형회귀 모델에 규제를 추가한 모델을 릿지와 라쏘라고 부른다.
릿지 : 계수를 제곱한 값을 기준
라쏘 : 계수의 절댓값을 기준
둘다 계수의 크기를 줄이지만 라쏘는 0으로 만들 수 도 있어서 릿지를 선호
#릿지 회귀
선형회귀에서 거의 완벽에 가까웠던 점수가 낮아졌다.
from sklearn.linear_model import Ridge
ridge = Ridge()
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
#0.9896101671037343테스트 세트 점수확인 ->정상
print(ridge.score(test_scaled, test_target))
#0.9790693977615391
릿지와 라쏘 모델을 사용할때 alpha값으로 규제의 양 조절 가능
값이 크면 규제 강도가 세진다 : 계수 값을 더 줄여 과소적합되도록 유도
작으면 : 계수를 줄이는 역할이 줄어들고 선형회귀 모델과 유사해지므로 과대적합될 가능성이 크다.
적절한 alpha 값을 찾으려면 결정계수 그래프 그려본다.
훈련세트와 테스트 세트의 점수가 가장 가까운 지점이 최적의 값이다.
alpha 값을 바꿀때마다 score() 메서드의 결과를 저장할 리스트를 만들자.
import matplotlib.pyplot as plt
train_score = []
test_score = []alpha 값을 10배씩 늘려가며 릿지 회귀 모델을 훈련한 다음
훈련세트와 테스트 세트의 점수를 파이썬 리스트에 저장
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
# 릿지 모델을 만듭니다
ridge = Ridge(alpha=alpha)
# 릿지 모델을 훈련합니다
ridge.fit(train_scaled, train_target)
# 훈련 점수와 테스트 점수를 저장합니다
train_score.append(ridge.score(train_scaled, train_target))
test_score.append(ridge.score(test_scaled, test_target))그래프 그리기
로그함수로 동일한 간격으로 호출
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R^2')
plt.show()훈련세트와 테스트 세트 점수차이가 아주 크다.
훈련세트에는 잘 맞고 테스트 세트에는 형편없는 과대적합
반대로 오른쪽은 훈련세트와 테스트세트 점수가 모두 낮아지는 과소적합
적절한 alpha 값은 두 그래프가 가장 가깝고 테스트 세트의 점수가 가장 높은 -1
즉 10의 -1승인 0.1 이다.
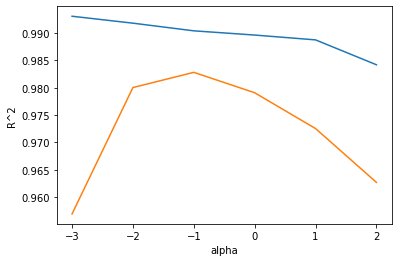
alpha값을 0.1로 하여 최종모델을 훈련하자
훈련세트와 테스트 세트의 점수가 비슷하게 높고 과대적합과 과소적합 사이에서 균형을 맞추고 있다.
ridge = Ridge(alpha=0.1)
ridge.fit(train_scaled, train_target)
print(ridge.score(train_scaled, train_target))
print(ridge.score(test_scaled, test_target))
"""
0.9903815817570365
0.9827976465386884
"""
#라쏘 회귀
Ridge 클래스를 Lasso클래스로 바꾸는게 전부다.
from sklearn.linear_model import Lasso
lasso = Lasso()
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target))
#0.989789897208096테스트 세트 점수
print(lasso.score(test_scaled, test_target))
#0.9800593698421883alpha로 규제강도 조절
train_score = []
test_score = []
alpha_list = [0.001, 0.01, 0.1, 1, 10, 100]
for alpha in alpha_list:
# 라쏘 모델을 만듭니다
lasso = Lasso(alpha=alpha, max_iter=10000)
# 라쏘 모델을 훈련합니다
lasso.fit(train_scaled, train_target)
# 훈련 점수와 테스트 점수를 저장합니다
train_score.append(lasso.score(train_scaled, train_target))
test_score.append(lasso.score(test_scaled, test_target))그래프 그리기
plt.plot(np.log10(alpha_list), train_score)
plt.plot(np.log10(alpha_list), test_score)
plt.xlabel('alpha')
plt.ylabel('R^2')
plt.show()최적 alpha 값 1 즉 10의 1승 =10

최적의 alpha값으로 모델 다시 훈련
좋은 결과다.
lasso = Lasso(alpha=10)
lasso.fit(train_scaled, train_target)
print(lasso.score(train_scaled, train_target))
print(lasso.score(test_scaled, test_target))
"""
0.9888067471131867
0.9824470598706695
"""
라쏘 모델의 계수는 coef_ 속성에 저장되어 있다.
이 중 0 인것을 헤아려 보겠다.
40개의 계수가 0이됐다..
55개의 특성을 모델에 주입했지만 라쏘모델이 사용한 특성은 달랑 15개
이러한 특징때문에 라쏘모델은 유용한 특성을 골라내는 용도로 사용할 수 있다.
print(np.sum(lasso.coef_ == 0))
# 40
'PYTHON > 데이터분석' 카테고리의 다른 글
| 4-2 확률적 경사 하강법 (0) | 2023.09.15 |
|---|---|
| 4-1 로지스틱 회귀 (0) | 2023.09.15 |
| 3-2 선형회귀 (0) | 2023.09.15 |
| 3-1 KNN 회귀 (0) | 2023.09.15 |
| 2-2 데이터 전처리 (0) | 2023.09.15 |



