
#확률적 경사 하강법
앞서 훈련한 모델을 버리지 않고 새로운 데이터에 대해서만 조금씩 더 훈련하기
전체 샘플을 사용하지 않고 딱 하나의 샘플을 훈련세트에서 랜덤하게 골라 가장 가파른 길을 찾아 최적의 장소로 이동
에포크
훈련세트를 한번씩 모두 사용해서 만족할 위치에 도달할때까지 내려간다.
미니배치 경사 하강법
무작의로 몇개의 샘플을 선택해서 경사 내려가기
배치경사 하강법
전체샘플 사용 -> 자원을 많이 사용하게 된다.
#손실 함수
가장 빠른 길을 찾아내려가려고 하는 산
어떤 문제에서 머신러닝 알고리즘이 얼마나 엉터리인지 측정하는 기준 -> 값이 작을수록 좋음
-> 어떤 값이 최솟값인지 모름
-> 많이 찾아보고 만족할만한 수준이면 다 내려왔다고 인정해야한다. = 확률적 경사하강법이 잘 맞는다.
#SGDClassifier
데이터 프레임 만들기
import pandas as pd
fish = pd.read_csv('https://bit.ly/fish_csv_data')
Species열=타겟데이터 , 나머지=입력데이터
fish_input = fish[['Weight','Length','Diagonal','Height','Width']].to_numpy()
fish_target = fish['Species'].to_numpy()
훈련세트, 테스트세트 나누기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(
fish_input, fish_target, random_state=42)
훈련세트, 테스트 세트의 특성 표준화 전처리
꼭 훈련세트에서 학습한 통계값으로 테스트 세트도 변환할 것
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input) #특성값의 스케일을 맞춘 넘파이 배열
test_scaled = ss.transform(test_input)
확률적 경사하강법 임포트
정확도가 낮다. 반복횟수가 모자라다.
from sklearn.linear_model import SGDClassifier
sc = SGDClassifier(loss='log', max_iter=10, random_state=42) #loss로 손실함수 지정 ,에포크 횟수=10
sc.fit(train_scaled, train_target)
#정확도 점수 출력
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
"""
0.773109243697479
0.775
"""
확률적 경사 하강법은 점진적 학습이 가능하므로 sc 모델을 추가로 더 훈련하자.
1 에포크씩 이어서 훈련할 수 있다.
모델을 이어서 훈련할 때는 pertial_fit()메서드를 사용한다.
sc.partial_fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
"""
0.8151260504201681
0.85
"""아직 점수가 낮지만 에크포를 한번 더 실행하니 정확도가 향상되었다.
여러 에포크에서 더 훈련할 필요가 있다.
무작정 많이 반복할 수는 없으니 기준이 필요하다.
#에포크와 과대 / 과소 적합
확률적 경사 하강법을 사용한 모델은 에포크 횟수에 따라 과소적합이나 과대적합이 될 수 있다.
횟수가 적으면 모델이 훈련세트를 덜 학습한다.
마치 산을 다 내려오지 못하고 훈련을 마치는 셈이다.
횟수가 많아야 훈련세트를 완전히 학습할 것이다. 훈련세트에 아주 잘맞는 모델이 만들어진다.
-> 과소적합된 모델일 가능성....
반대로 많은 에포크횟수
->훈련세트에 너무 잘맞아 테스트 세트에는 점수가 나쁜 과대적합 모델일 가능성..
조기종료
과대적합이 시작하기 전에 훈련을 멈추자
import numpy as np
sc = SGDClassifier(loss='log', random_state=42)
train_score = []
test_score = []
classes = np.unique(train_target)에포크 300번
for _ in range(0, 300):
sc.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(sc.score(train_scaled, train_target))
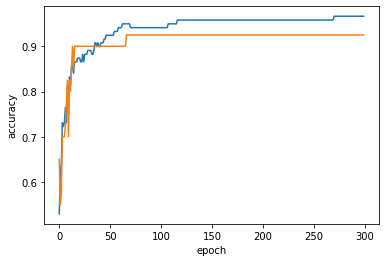
test_score.append(sc.score(test_scaled, test_target))그래프
100번째 에포크 이후에는 훈련세트와 테스트세트의 점수가 조금씩 벌어지는 중
100이 적합
import matplotlib.pyplot as plt
plt.plot(train_score)
plt.plot(test_score)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
100으로 다시 훈련
sc = SGDClassifier(loss='log', max_iter=100, tol=None, random_state=42)
sc.fit(train_scaled, train_target)
print(sc.score(train_scaled, train_target))
print(sc.score(test_scaled, test_target))
"""
0.957983193277311
0.925
"""
'PYTHON > 데이터분석' 카테고리의 다른 글
| 5-1 결정 트리 (0) | 2023.09.15 |
|---|---|
| 4-1 로지스틱 회귀 (0) | 2023.09.15 |
| 3-3 특성 공학과 규제 (0) | 2023.09.15 |
| 3-2 선형회귀 (0) | 2023.09.15 |
| 3-1 KNN 회귀 (0) | 2023.09.15 |



